В течение последних двух лет мы слышали об Ampere следующего поколения от NVIDIA, но компания наконец-то готова рассказать о своей графической архитектуре следующего поколения. Хотя сегодня вы не услышите никакой информации о потребительских игровых видеокартах серии GeForce RTX 30, NVIDIA обсуждает детали Ampere для рынков центров обработки данных машинного обучения и HPC. Короче говоря, эта версия Ampere-самый большой и мощный графический процессор, который когда-либо производила NVIDIA, и компания предлагает, что это также самый большой в мире 7-нм чип. Без сомнения, он очень массивный.
По данным NVIDIA, ее графический процессор AmpereA100 уже полностью запущен в производство и поставляется заказчикам, и компания утверждает, что A100 представляет собой самый большой подъем производительности графических процессоров в поколении за всю свою историю. Учитывая технические характеристики, у нас нет причин сомневаться в компании.

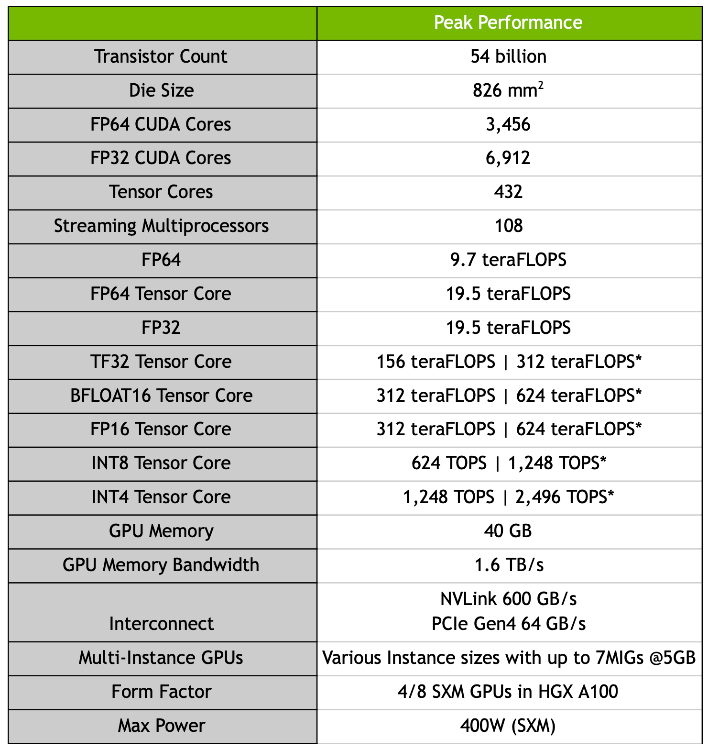
A100 имеет колоссальные 54 миллиарда транзисторов, что, безусловно, позволяет ему взять корону в качестве крупнейшего в мире процессора, построенного на 7 нм технологии. Есть в общей сложности 6 912 FP32 CUDA ядер, 432 тензорных ядер и 108 SMs. На борту находится 40 ГБ памяти HBM2e с максимальной пропускной способностью памяти 1,6 ТБ/сек. FP32 compute поставляется с ошеломляющими 19,5 TLFLOPs по сравнению с 16,4 TFLOPs для Tesla V100s. FP64 compute составляет 9,7 TFLOPs по сравнению с 8,2 TFLOPs для Tesla V100s. Кроме того, его тензорные ядра используют точность FP32, которая позволяет повысить производительность AI в 20 раз. Когда дело доходит до производительности FP64, эти тензорные ядра также обеспечивают повышение производительности в 2,5 раза по сравнению с его предшественником Volta в отношении приложений HPC (High Performance Compute).
Некоторые другие специфические для Ампера функции включают многоэкземплярный графический процессор, он же MIG, который позволяет разрезать графический процессор A100 на семь дискретных экземпляров. Таким образом, необработанная мощность чипа может быть подготовлена для нескольких дискретных специализированных рабочих нагрузок. Ampere также интегрирует конструкцию NVLink третьего поколения, которая удваивает производительность межсоединений между несколькими графическими процессорами для улучшения масштабирования.
“Графический процессор NVIDIA A100 — это 20-кратный скачок производительности ИИ и сквозной ускоритель машинного обучения-от анализа данных до обучения и вывода»,-сказал основатель и генеральный директор NVIDIA Дженсен Хуан. «Впервые масштабирование и масштабирование рабочих нагрузок может быть ускорено на одной платформе. NVIDIA A100 одновременно повысит пропускную способность и снизит стоимость центров обработки данных.”
 NVIDIA DGX A100
NVIDIA DGX A100
Эти графические процессоры A100 также войдут в DGX третьего поколения NVIDIA Суперкомпьютер ИИ, с 5 петафлопсами производительности ИИ. Дженсен дал нам ранний «вкус» DGX A100, когда во вторник вытащил свежеиспеченную установку из своей личной домашней печи. В то время он заявил, что это “самая большая в мире видеокарта», но, к сожалению, ее целевые функции не предназначены для игр.
DGX A100 имеет в общей сложности восемь графических процессоров A100, а также 320 ГБ памяти (пропускная способность 12,4 ТБ в секунду). Система также оснащена интерконнектами Mellanox HDR 200 Гбит / с. Как мы уже упоминали ранее, каждый графический процессор A100 может поддерживать до 7 экземпляров, а это означает, что с 8 графическими процессорами на борту DGX A100 может поддерживать в общей сложности 56 экземпляров для атаки на текущую рабочую нагрузку.

Однако NVIDIA также думает не только о DGX A100 и объявила о разработке DGX SuperPod, который сочетает в себе мощность 140 систем DGX A100, связанных с помощью вышеупомянутых межсоединений Mellanox. Вместе вы смотрите на 700 петафлопс вычислительной мощности ИИ, которые могут быть использованы для чего угодно-от медицинских исследований до помощи в анализе COVID-19, как мы видели в проекте Folding@Home.
NVIDIA, похоже, начинает активно работать с Ampere и A100, но мы, конечно, также с нетерпением ждем того, что компания готовит для рынка энтузиастов. Прошло уже более 18 месяцев с тех пор, как NVIDIA запустила свою архитектуру Тьюринга с семейством GeForce RTX 20, и ожидания от семейства GeForce RTX 30 невероятно высоки.
Источник: https://hothardware.com/news/nvidia-ampere-dgx-a100-ai-machine-learning